📌 TOPINDIATOURS Breaking ai: Adobe Research Unlocking Long-Term Memory in Video Wo
Video world models, which predict future frames conditioned on actions, hold immense promise for artificial intelligence, enabling agents to plan and reason in dynamic environments. Recent advancements, particularly with video diffusion models, have shown impressive capabilities in generating realistic future sequences. However, a significant bottleneck remains: maintaining long-term memory. Current models struggle to remember events and states from far in the past due to the high computational cost associated with processing extended sequences using traditional attention layers. This limits their ability to perform complex tasks requiring sustained understanding of a scene.
A new paper, “Long-Context State-Space Video World Models” by researchers from Stanford University, Princeton University, and Adobe Research, proposes an innovative solution to this challenge. They introduce a novel architecture that leverages State-Space Models (SSMs) to extend temporal memory without sacrificing computational efficiency.
The core problem lies in the quadratic computational complexity of attention mechanisms with respect to sequence length. As the video context grows, the resources required for attention layers explode, making long-term memory impractical for real-world applications. This means that after a certain number of frames, the model effectively “forgets” earlier events, hindering its performance on tasks that demand long-range coherence or reasoning over extended periods.
The authors’ key insight is to leverage the inherent strengths of State-Space Models (SSMs) for causal sequence modeling. Unlike previous attempts that retrofitted SSMs for non-causal vision tasks, this work fully exploits their advantages in processing sequences efficiently.
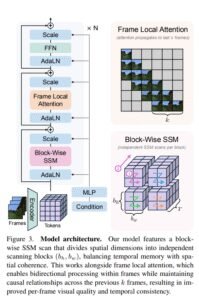
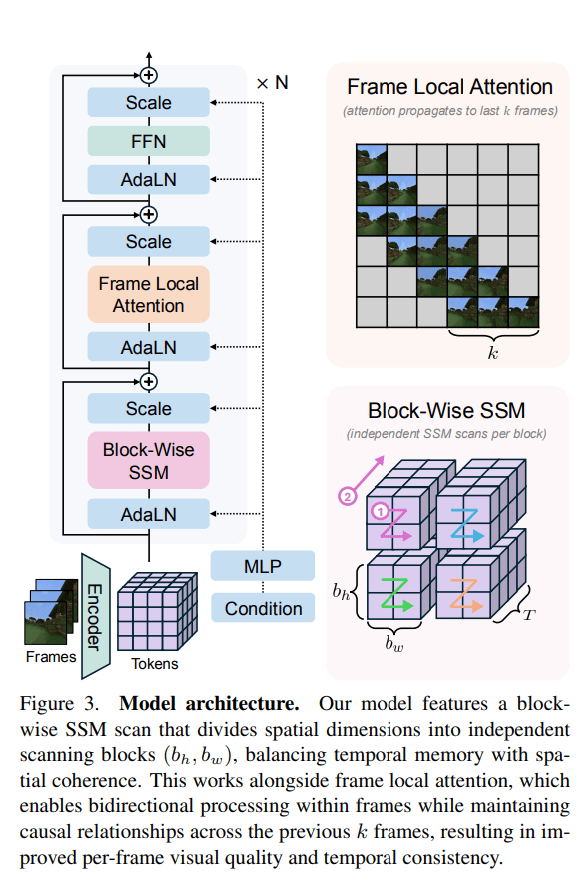
The proposed Long-Context State-Space Video World Model (LSSVWM) incorporates several crucial design choices:
- Block-wise SSM Scanning Scheme: This is central to their design. Instead of processing the entire video sequence with a single SSM scan, they employ a block-wise scheme. This strategically trades off some spatial consistency (within a block) for significantly extended temporal memory. By breaking down the long sequence into manageable blocks, they can maintain a compressed “state” that carries information across blocks, effectively extending the model’s memory horizon.
- Dense Local Attention: To compensate for the potential loss of spatial coherence introduced by the block-wise SSM scanning, the model incorporates dense local attention. This ensures that consecutive frames within and across blocks maintain strong relationships, preserving the fine-grained details and consistency necessary for realistic video generation. This dual approach of global (SSM) and local (attention) processing allows them to achieve both long-term memory and local fidelity.
The paper also introduces two key training strategies to further improve long-context performance:
- Diffusion Forcing: This technique encourages the model to generate frames conditioned on a prefix of the input, effectively forcing it to learn to maintain consistency over longer durations. By sometimes not sampling a prefix and keeping all tokens noised, the training becomes equivalent to diffusion forcing, which is highlighted as a special case of long-context training where the prefix length is zero. This pushes the model to generate coherent sequences even from minimal initial context.
- Frame Local Attention: For faster training and sampling, the authors implemented a “frame local attention” mechanism. This utilizes FlexAttention to achieve significant speedups compared to a fully causal mask. By grouping frames into chunks (e.g., chunks of 5 with a frame window size of 10), frames within a chunk maintain bidirectionality while also attending to frames in the previous chunk. This allows for an effective receptive field while optimizing computational load.
The researchers evaluated their LSSVWM on challenging datasets, including Memory Maze and Minecraft, which are specifically designed to test long-term memory capabilities through spatial retrieval and reasoning tasks.
The experiments demonstrate that their approach substantially surpasses baselines in preserving long-range memory. Qualitative results, as shown in supplementary figures (e.g., S1, S2, S3), illustrate that LSSVWM can generate more coherent and accurate sequences over extended periods compared to models relying solely on causal attention or even Mamba2 without frame local attention. For instance, on reasoning tasks for the maze dataset, their model maintains better consistency and accuracy over long horizons. Similarly, for retrieval tasks, LSSVWM shows improved ability to recall and utilize information from distant past frames. Crucially, these improvements are achieved while maintaining practical inference speeds, making the models suitable for interactive applications.
The Paper Long-Context State-Space Video World Models is on arXiv
The post Adobe Research Unlocking Long-Term Memory in Video World Models with State-Space Models first appeared on Synced.
🔗 Sumber: syncedreview.com
📌 TOPINDIATOURS Update ai: Mark Zuckerberg’s Former Top AI Scientist Reveals Exact
In a new interview with The Financial Times, Yann LeCun, one of the so-called godfathers of AI, finally dished on his abrupt exit from Meta in November.
From how he tells it, most of it boils down to his increasingly fraught relationship with CEO Mark Zuckerberg — and his new golden boy, Alexandr Wang, who ended up bossing LeCun around even though he’s nearly four decades younger.
LeCun had been at Zuckerberg’s company for over a decade, where, as chief AI scientist, he had the freedom to carry out all kinds of esoteric AI research without necessarily having to worry about developing a profitable product. LeCun described Meta, then Facebook, as a “tabula rasa with a carte blanche.” “Money was clearly not going to be a problem,” he told the FT.
Then, in November 2022, ChatGPT came out, and the whole world went bananas for AI chatbots. AI chatbots and their human-like capabilities for conversation are powered by large language models, something LeCun helped pioneer with his foundational work on neural networks. When Zuckerberg ordered LeCun develop Meta’s own LLM, he agreed under the condition that Llama would be open source and free.
The Llama models “changed the entire industry,” LeCun said, and were a hit with AI researchers because of their power and open source nature.
The success didn’t last, though; the latest Llama 4 model, released last April, was dead on arrival and reviled as an instantly-outdated flop. LeCun blames the failure on Zuckerberg pressuring LeCun’s unit to accelerate AI development.
“We had a lot of new ideas and really cool stuff that they should implement. But they were just going for things that were essentially safe and proved,” LeCun told the FT. “When you do this, you fall behind.”
The rift, however, goes deeper. LeCun views LLMs as a “dead end” for building even more powerful, “superintelligent” models that rival or surpass human capabilities. An entirely different architecture called “world models” which seek to understand the physical world, not just language, is needed to make the next major leap in the tech.
According to LeCun, Zuckerberg actually liked LeCun’s world model research, but didn’t put his money where his mouth is. Instead, Zuckerberg launched a new LLM-focused Superintelligence Labs last year, separate from LeCun’s lab, and offered several hundred million dollar contracts to attract top talent. All the talent that came in, LeCun complained, have been “completely LLM-pilled.”
Zuckerberg’s marquee new-hire was Alexandr Wang, the founder and former CEO of the AI data annotation startup Scale AI, which provides an essential service for training AI models, but doesn’t build or design them. Zuckerberg poured $14 billion into Scale AI to buy a 49 percent stake and, as part of that deal, Wang left and joined Meta to lead the new Superintelligence Labs. As a consequence, LeCun was forced to start reporting to Wang.
The move raised questions from the get-go, including whether Wang, 29, had the experience and background to build massive AI models, something his company didn’t do. LeCun doesn’t leave us wondering where he stands on Wang’s hiring, calling him “young” and “inexperienced.”
Be that as it may, LeCun, considered to be a godfather of the entire field, was now taking orders from Wang. LeCun seemed cool about this at first when the interviewer brought up the new hierarchy. “The average age of a Facebook engineer at the time was 27,” Lecun told the FT. “I was twice the age of the average engineer.”
But when the interviewer pointed out that the younger generation weren’t telling him what to do until the 29-year-old Wang showed up, LeCun seemingly let his true feelings be known.
“Alex isn’t telling me what to do either,” LeCun sneered. “You don’t tell a researcher what to do. You certainly don’t tell a researcher like me what to do.”
He’ll be his own boss going forward. LeCun has launched a new world-model-focused startup called Advanced Machine Intelligence Labs, which is targeting a $3 billion valuation. LeCun will serve as executive chairman, allowing him a similar degree of freedom to pursue research he once enjoyed at Meta, according to the FT.
More on AI: Cops Forced to Explain Why AI Generated Police Report Claimed Officer Transformed Into Frog
The post Mark Zuckerberg’s Former Top AI Scientist Reveals Exactly Why He Quit appeared first on Futurism.
🔗 Sumber: futurism.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!