📌 TOPINDIATOURS Breaking ai: Scientists Preparing to Simulate Human Brain on Super
In 2024, researchers completed the first-ever map of the circuitry of a fruit fly’s brain.
Despite its diminutive size, the organ packs almost 500 feet of wiring and 54.5 million synapses into the size of a grain of sand — an astonishing feat of computational neurology research that allows scientists to better understand how signals travel throughout the brain.
And thanks to significant advances of some of the world’s most capable supercomputers, researchers at the Jülich Research Centre in Germany are now aiming their sights at a far more ambitious goal: a simulation at the scale of the entire human brain.
Previous attempts, dating back a decade, like the Human Brain Project, fell largely flat, despite considerable government funding. But as New Scientist reports, the Jülich researchers think they can push things forward. The idea is to bring together several models of smaller regions of the brain with a supercomputer to run simulations of billions of firing neurons.
The team, which is being led by Jülich neurophysics professor Markus Diesmann, will leverage the Joint Undertaking Pioneer for Innovative and Transformative Exascale Research (JUPITER) supercomputer for their simulation.
JUPITER is currently the fourth most powerful supercomputer in the world according to the TOP500 list, and features thousands of graphical processing units.
The team demonstrated last month that a “spiking neural network” could be scaled up and run on JUPITER, effectively matching the cerebral cortex’s 20 billion neurons and 100 trillion connections.
Once up and running, the simulation could be a major upgrade, Diesmann told New Scientist, compared to previous, much smaller simulations.
“We know now that large networks can do qualitatively different things than small ones,” he said. “It’s clear the large networks are different.”
At the end of the day, we’re still only scratching the surface of an organ that remains mysterious to scientists. Even simulations at the scale of a human brain will only teach us so much about how it functions.
“We can’t actually build brains,” University of Sussex mathematical physics professor Thomas Nowotny told New Scientist. “Even if we can make simulations of the size of a brain, we can’t make simulations of the brain.”
More on brain simulations: People Are Horrified by Lab-Grown Human Brains
The post Scientists Preparing to Simulate Human Brain on Supercomputer appeared first on Futurism.
🔗 Sumber: futurism.com
📌 TOPINDIATOURS Eksklusif ai: Adobe Research Unlocking Long-Term Memory in Video W
Video world models, which predict future frames conditioned on actions, hold immense promise for artificial intelligence, enabling agents to plan and reason in dynamic environments. Recent advancements, particularly with video diffusion models, have shown impressive capabilities in generating realistic future sequences. However, a significant bottleneck remains: maintaining long-term memory. Current models struggle to remember events and states from far in the past due to the high computational cost associated with processing extended sequences using traditional attention layers. This limits their ability to perform complex tasks requiring sustained understanding of a scene.
A new paper, “Long-Context State-Space Video World Models” by researchers from Stanford University, Princeton University, and Adobe Research, proposes an innovative solution to this challenge. They introduce a novel architecture that leverages State-Space Models (SSMs) to extend temporal memory without sacrificing computational efficiency.
The core problem lies in the quadratic computational complexity of attention mechanisms with respect to sequence length. As the video context grows, the resources required for attention layers explode, making long-term memory impractical for real-world applications. This means that after a certain number of frames, the model effectively “forgets” earlier events, hindering its performance on tasks that demand long-range coherence or reasoning over extended periods.
The authors’ key insight is to leverage the inherent strengths of State-Space Models (SSMs) for causal sequence modeling. Unlike previous attempts that retrofitted SSMs for non-causal vision tasks, this work fully exploits their advantages in processing sequences efficiently.
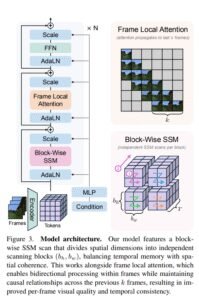
The proposed Long-Context State-Space Video World Model (LSSVWM) incorporates several crucial design choices:
- Block-wise SSM Scanning Scheme: This is central to their design. Instead of processing the entire video sequence with a single SSM scan, they employ a block-wise scheme. This strategically trades off some spatial consistency (within a block) for significantly extended temporal memory. By breaking down the long sequence into manageable blocks, they can maintain a compressed “state” that carries information across blocks, effectively extending the model’s memory horizon.
- Dense Local Attention: To compensate for the potential loss of spatial coherence introduced by the block-wise SSM scanning, the model incorporates dense local attention. This ensures that consecutive frames within and across blocks maintain strong relationships, preserving the fine-grained details and consistency necessary for realistic video generation. This dual approach of global (SSM) and local (attention) processing allows them to achieve both long-term memory and local fidelity.
The paper also introduces two key training strategies to further improve long-context performance:
- Diffusion Forcing: This technique encourages the model to generate frames conditioned on a prefix of the input, effectively forcing it to learn to maintain consistency over longer durations. By sometimes not sampling a prefix and keeping all tokens noised, the training becomes equivalent to diffusion forcing, which is highlighted as a special case of long-context training where the prefix length is zero. This pushes the model to generate coherent sequences even from minimal initial context.
- Frame Local Attention: For faster training and sampling, the authors implemented a “frame local attention” mechanism. This utilizes FlexAttention to achieve significant speedups compared to a fully causal mask. By grouping frames into chunks (e.g., chunks of 5 with a frame window size of 10), frames within a chunk maintain bidirectionality while also attending to frames in the previous chunk. This allows for an effective receptive field while optimizing computational load.
The researchers evaluated their LSSVWM on challenging datasets, including Memory Maze and Minecraft, which are specifically designed to test long-term memory capabilities through spatial retrieval and reasoning tasks.
The experiments demonstrate that their approach substantially surpasses baselines in preserving long-range memory. Qualitative results, as shown in supplementary figures (e.g., S1, S2, S3), illustrate that LSSVWM can generate more coherent and accurate sequences over extended periods compared to models relying solely on causal attention or even Mamba2 without frame local attention. For instance, on reasoning tasks for the maze dataset, their model maintains better consistency and accuracy over long horizons. Similarly, for retrieval tasks, LSSVWM shows improved ability to recall and utilize information from distant past frames. Crucially, these improvements are achieved while maintaining practical inference speeds, making the models suitable for interactive applications.
The Paper Long-Context State-Space Video World Models is on arXiv
The post Adobe Research Unlocking Long-Term Memory in Video World Models with State-Space Models first appeared on Synced.
🔗 Sumber: syncedreview.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!