📌 TOPINDIATOURS Hot ai: Adobe Research Unlocking Long-Term Memory in Video World M
Video world models, which predict future frames conditioned on actions, hold immense promise for artificial intelligence, enabling agents to plan and reason in dynamic environments. Recent advancements, particularly with video diffusion models, have shown impressive capabilities in generating realistic future sequences. However, a significant bottleneck remains: maintaining long-term memory. Current models struggle to remember events and states from far in the past due to the high computational cost associated with processing extended sequences using traditional attention layers. This limits their ability to perform complex tasks requiring sustained understanding of a scene.
A new paper, “Long-Context State-Space Video World Models” by researchers from Stanford University, Princeton University, and Adobe Research, proposes an innovative solution to this challenge. They introduce a novel architecture that leverages State-Space Models (SSMs) to extend temporal memory without sacrificing computational efficiency.
The core problem lies in the quadratic computational complexity of attention mechanisms with respect to sequence length. As the video context grows, the resources required for attention layers explode, making long-term memory impractical for real-world applications. This means that after a certain number of frames, the model effectively “forgets” earlier events, hindering its performance on tasks that demand long-range coherence or reasoning over extended periods.
The authors’ key insight is to leverage the inherent strengths of State-Space Models (SSMs) for causal sequence modeling. Unlike previous attempts that retrofitted SSMs for non-causal vision tasks, this work fully exploits their advantages in processing sequences efficiently.
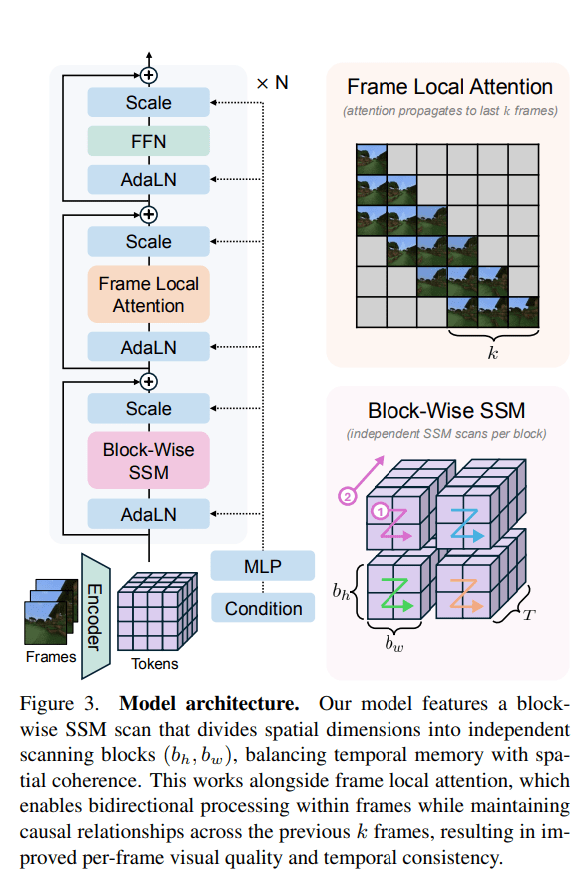
The proposed Long-Context State-Space Video World Model (LSSVWM) incorporates several crucial design choices:
- Block-wise SSM Scanning Scheme: This is central to their design. Instead of processing the entire video sequence with a single SSM scan, they employ a block-wise scheme. This strategically trades off some spatial consistency (within a block) for significantly extended temporal memory. By breaking down the long sequence into manageable blocks, they can maintain a compressed “state” that carries information across blocks, effectively extending the model’s memory horizon.
- Dense Local Attention: To compensate for the potential loss of spatial coherence introduced by the block-wise SSM scanning, the model incorporates dense local attention. This ensures that consecutive frames within and across blocks maintain strong relationships, preserving the fine-grained details and consistency necessary for realistic video generation. This dual approach of global (SSM) and local (attention) processing allows them to achieve both long-term memory and local fidelity.
The paper also introduces two key training strategies to further improve long-context performance:
- Diffusion Forcing: This technique encourages the model to generate frames conditioned on a prefix of the input, effectively forcing it to learn to maintain consistency over longer durations. By sometimes not sampling a prefix and keeping all tokens noised, the training becomes equivalent to diffusion forcing, which is highlighted as a special case of long-context training where the prefix length is zero. This pushes the model to generate coherent sequences even from minimal initial context.
- Frame Local Attention: For faster training and sampling, the authors implemented a “frame local attention” mechanism. This utilizes FlexAttention to achieve significant speedups compared to a fully causal mask. By grouping frames into chunks (e.g., chunks of 5 with a frame window size of 10), frames within a chunk maintain bidirectionality while also attending to frames in the previous chunk. This allows for an effective receptive field while optimizing computational load.
The researchers evaluated their LSSVWM on challenging datasets, including Memory Maze and Minecraft, which are specifically designed to test long-term memory capabilities through spatial retrieval and reasoning tasks.
The experiments demonstrate that their approach substantially surpasses baselines in preserving long-range memory. Qualitative results, as shown in supplementary figures (e.g., S1, S2, S3), illustrate that LSSVWM can generate more coherent and accurate sequences over extended periods compared to models relying solely on causal attention or even Mamba2 without frame local attention. For instance, on reasoning tasks for the maze dataset, their model maintains better consistency and accuracy over long horizons. Similarly, for retrieval tasks, LSSVWM shows improved ability to recall and utilize information from distant past frames. Crucially, these improvements are achieved while maintaining practical inference speeds, making the models suitable for interactive applications.
The Paper Long-Context State-Space Video World Models is on arXiv
The post Adobe Research Unlocking Long-Term Memory in Video World Models with State-Space Models first appeared on Synced.
🔗 Sumber: syncedreview.com
📌 TOPINDIATOURS Hot ai: Railway secures $100 million to challenge AWS with AI-nati
Railway, a San Francisco-based cloud platform that has quietly amassed two million developers without spending a dollar on marketing, announced Thursday that it raised $100 million in a Series B funding round, as surging demand for artificial intelligence applications exposes the limitations of legacy cloud infrastructure.
TQ Ventures led the round, with participation from FPV Ventures, Redpoint, and Unusual Ventures. The investment values Railway as one of the most significant infrastructure startups to emerge during the AI boom, capitalizing on developer frustration with the complexity and cost of traditional platforms like Amazon Web Services and Google Cloud.
"As AI models get better at writing code, more and more people are asking the age-old question: where, and how, do I run my applications?" said Jake Cooper, Railway's 28-year-old founder and chief executive, in an exclusive interview with VentureBeat. "The last generation of cloud primitives were slow and outdated, and now with AI moving everything faster, teams simply can't keep up."
The funding is a dramatic acceleration for a company that has charted an unconventional path through the cloud computing industry. Railway raised just $24 million in total before this round, including a $20 million Series A from Redpoint in 2022. The company now processes more than 10 million deployments monthly and handles over one trillion requests through its edge network — metrics that rival far larger and better-funded competitors.
Why three-minute deploy times have become unacceptable in the age of AI coding assistants
Railway's pitch rests on a simple observation: the tools developers use to deploy and manage software were designed for a slower era. A standard build-and-deploy cycle using Terraform, the industry-standard infrastructure tool, takes two to three minutes. That delay, once tolerable, has become a critical bottleneck as AI coding assistants like Claude, ChatGPT, and Cursor can generate working code in seconds.
"When godly intelligence is on tap and can solve any problem in three seconds, those amalgamations of systems become bottlenecks," Cooper told VentureBeat. "What was really cool for humans to deploy in 10 seconds or less is now table stakes for agents."
The company claims its platform delivers deployments in under one second — fast enough to keep pace with AI-generated code. Customers report a tenfold increase in developer velocity and up to 65 percent cost savings compared to traditional cloud providers.
These numbers come directly from enterprise clients, not internal benchmarks. Daniel Lobaton, chief technology officer at G2X, a platform serving 100,000 federal contractors, measured deployment speed improvements of seven times faster and an 87 percent cost reduction after migrating to Railway. His infrastructure bill dropped from $15,000 per month to approximately $1,000.
"The work that used to take me a week on our previous infrastructure, I can do in Railway in like a day," Lobaton said. "If I want to spin up a new service and test different architectures, it would take so long on our old setup. In Railway I can launch six services in two minutes."
Inside the controversial decision to abandon Google Cloud and build data centers from scratch
What distinguishes Railway from competitors like Render and Fly.io is the depth of its vertical integration. In 2024, the company made the unusual decision to abandon Google Cloud entirely and build its own data centers, a move that echoes the famous Alan Kay maxim: "People who are really serious about software should make their own hardware."
"We wanted to design hardware in a way where we could build a differentiated experience," Cooper said. "Having full control over the network, compute, and storage layers lets us do really fast build and deploy loops, the kind that allows us to move at 'agentic speed' while staying 100 percent the smoothest ride in town."
The approach paid dividends during recent widespread outages that affected major cloud providers — Railway remained online throughout.
This soup-to-nuts control enables pricing that undercuts the hyperscalers by roughly 50 percent and newer cloud startups by three to four times. Railway charges by the second for actual compute usage: $0.00000386 per gigabyte-second of memory, $0.00000772 per vCPU-second, and $0.00000006 per gigabyte-second of storage. There are no charges for idle virtual machines — a stark contrast to the traditional cloud model where customers pay for provisioned capacity whether they use it or not.
"The conventional wisdom is that the big guys have economies of scale to offer better pricing," Cooper noted. "But when they're charging for VMs that usually sit idle in the cloud, and we've purpose-built everything to fit much more density on these machines, you have a big opportunity."
How 30 employees built a platform generating tens of millions in annual revenue
Railway has achieved its scale with a team of just 30 employees generating tens of millions in annual revenue — a ratio of revenue per employee that would be exceptional even for established software companies. The company grew revenue 3.5 times last year and continues to expand at 15 percent month-over-month.
Cooper emphasized that the fundraise was strategic rather than necessary. "We're default alive; there's no reason for us to raise money," he said. "We raised because we see a massive opportunity to accelerate, not because we needed to survive."
The company hired its first salesperson only last year and employs just two solutions engineers. Nearly all of Railway's two million users discovered the platform through word of mouth — developers telling other developers about a tool that actually works.
"We basically did the standard engineering thing: if you build it, they will come," Cooper recalled. "And to some degree, they came."
From side projects to Fortune 500 deployments: Railway's unlikely corporate expansion
Despite its grassroots developer community, Railway has made significant inroads into large organizations. The company claims that 31 percent of Fortune 500 companies now use its platform, though deployments range from company-wide infrastructure to individual team projects.
Notable customers include Bilt, the loyalty program company; Intuit's GoCo subsidiary; TripAdvisor's Cruise Critic; and MGM Resorts. Kernel, a Y Combinator-backed startup providing AI infrastructure to over 1,000 companies, runs its entire customer-facing system on Railway for $444 per month.
"At my previous company Clever, which sold …
Konten dipersingkat otomatis.
🔗 Sumber: venturebeat.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!