📌 TOPINDIATOURS Eksklusif ai: Listen Labs raises $69M after viral billboard hiring
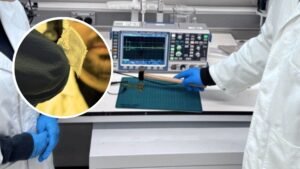
Alfred Wahlforss was running out of options. His startup, Listen Labs, needed to hire over 100 engineers, but competing against Mark Zuckerberg's $100 million offers seemed impossible. So he spent $5,000 — a fifth of his marketing budget — on a billboard in San Francisco displaying what looked like gibberish: five strings of random numbers.
The numbers were actually AI tokens. Decoded, they led to a coding challenge: build an algorithm to act as a digital bouncer at Berghain, the Berlin nightclub famous for rejecting nearly everyone at the door. Within days, thousands attempted the puzzle. 430 cracked it. Some got hired. The winner flew to Berlin, all expenses paid.
That unconventional approach has now attracted $69 million in Series B funding, led by Ribbit Capital with participation from Evantic and existing investors Sequoia Capital, Conviction, and Pear VC. The round values Listen Labs at $500 million and brings its total capital to $100 million. In nine months since launch, the company has grown annualized revenue by 15x to eight figures and conducted over one million AI-powered interviews.
"When you obsess over customers, everything else follows," Wahlforss said in an interview with VentureBeat. "Teams that use Listen bring the customer into every decision, from marketing to product, and when the customer is delighted, everyone is."
Why traditional market research is broken, and what Listen Labs is building to fix it
Listen's AI researcher finds participants, conducts in-depth interviews, and delivers actionable insights in hours, not weeks. The platform replaces the traditional choice between quantitative surveys — which provide statistical precision but miss nuance—and qualitative interviews, which deliver depth but cannot scale.
Wahlforss explained the limitation of existing approaches: "Essentially surveys give you false precision because people end up answering the same question… You can't get the outliers. People are actually not honest on surveys." The alternative, one-on-one human interviews, "gives you a lot of depth. You can ask follow up questions. You can kind of double check if they actually know what they're talking about. And the problem is you can't scale that."
The platform works in four steps: users create a study with AI assistance, Listen recruits participants from its global network of 30 million people, an AI moderator conducts in-depth interviews with follow-up questions, and results are packaged into executive-ready reports including key themes, highlight reels, and slide decks.
What distinguishes Listen's approach is its use of open-ended video conversations rather than multiple-choice forms. "In a survey, you can kind of guess what you should answer, and you have four options," Wahlforss said. "Oh, they probably want me to buy high income. Let me click on that button versus an open ended response. It just generates much more honesty."
The dirty secret of the $140 billion market research industry: rampant fraud
Listen finds and qualifies the right participants in its global network of 30 million people. But building that panel required confronting what Wahlforss called "one of the most shocking things that we've learned when we entered this industry"—rampant fraud.
"Essentially, there's a financial transaction involved, which means there will be bad players," he explained. "We actually had some of the largest companies, some of them have billions in revenue, send us people who claim to be kind of enterprise buyers to our platform and our system immediately detected, like, fraud, fraud, fraud, fraud, fraud."
The company built what it calls a "quality guard" that cross-references LinkedIn profiles with video responses to verify identity, checks consistency across how participants answer questions, and flags suspicious patterns. The result, according to Wahlforss: "People talk three times more. They're much more honest when they talk about sensitive topics like politics and mental health."
Emeritus, an online education company that uses Listen, reported that approximately 20% of survey responses previously fell into the fraudulent or low-quality category. With Listen, they reduced this to almost zero. "We did not have to replace any responses because of fraud or gibberish information," said Gabrielli Tiburi, Assistant Manager of Customer Insights at Emeritus.
How Microsoft, Sweetgreen, and Chubbies are using AI interviews to build better products
The speed advantage has proven central to Listen's pitch. Traditional customer research at Microsoft could take four to six weeks to generate insights. "By the time we get to them, either the decision has been made or we lose out on the opportunity to actually influence it," said Romani Patel, Senior Research Manager at Microsoft.
With Listen, Microsoft can now get insights in days, and in many cases, within hours.
The platform has already powered several high-profile initiatives. Microsoft used Listen Labs to collect global customer stories for its 50th anniversary celebration. "We wanted users to share how Copilot is empowering them to bring their best self forward," Patel said, "and we were able to collect those user video stories within a day." Traditionally, that kind of work would have taken six to eight weeks.
Simple Modern, an Oklahoma-based drinkware company, used Listen to test a new product concept. The process took about an hour to write questions, an hour to launch the study, and 2.5 hours to receive feedback from 120 people across the country. "We went from 'Should we even have this product?' to 'How should we launch it?'" said Chris Hoyle, the company's Chief Marketing Officer.
Chubbies, the shorts brand, achieved a 24x increase in youth research participation—growing from 5 to 120 participants — by using Listen to overcome the scheduling challenges of traditional focus groups with children. "There's school, sports, dinner, and homework," explained Lauren Neville, Director of Insights and Innovation. "I had to find a way to hear from them that fit into their schedules."
The company also discovered product issues through AI interviews that might have gone undetected otherwise. Wahlforss described how the AI "through conversations, realized there were like issues with the the kids short line, and decided to, like, interview hundreds of kids. And I understand that there were issues in the liner of the shorts and that they were, like, scratchy, quote, unquote, according to the people interviewed." The redesigned product became "a blockbuster hit."
The Jevons paradox explains why cheaper research creates more demand, not less
Listen Labs is entering a massive but fragmented market. Wahlforss cited research from Andreessen Horowitz estimating the market research ind…
Konten dipersingkat otomatis.
🔗 Sumber: venturebeat.com
📌 TOPINDIATOURS Breaking ai: Which Agent Causes Task Failures and When?Researchers
Share My Research is Synced’s column that welcomes scholars to share their own research breakthroughs with over 1.5M global AI enthusiasts. Beyond technological advances, Share My Research also calls for interesting stories behind the research and exciting research ideas. Contact us: chain.zhang@jiqizhixin.com
Meet the authors
Institutions: Penn State University, Duke University, Google DeepMind, University of Washington, Meta, Nanyang Technological University, and Oregon State University. The co-first authors are Shaokun Zhang of Penn State University and Ming Yin of Duke University.
In recent years, LLM Multi-Agent systems have garnered widespread attention for their collaborative approach to solving complex problems. However, it’s a common scenario for these systems to fail at a task despite a flurry of activity. This leaves developers with a critical question: which agent, at what point, was responsible for the failure? Sifting through vast interaction logs to pinpoint the root cause feels like finding a needle in a haystack—a time-consuming and labor-intensive effort.
This is a familiar frustration for developers. In increasingly complex Multi-Agent systems, failures are not only common but also incredibly difficult to diagnose due to the autonomous nature of agent collaboration and long information chains. Without a way to quickly identify the source of a failure, system iteration and optimization grind to a halt.
To address this challenge, researchers from Penn State University and Duke University, in collaboration with institutions including Google DeepMind, have introduced the novel research problem of “Automated Failure Attribution.” They have constructed the first benchmark dataset for this task, Who&When, and have developed and evaluated several automated attribution methods. This work not only highlights the complexity of the task but also paves a new path toward enhancing the reliability of LLM Multi-Agent systems.
The paper has been accepted as a Spotlight presentation at the top-tier machine learning conference, ICML 2025, and the code and dataset are now fully open-source.
Paper:https://arxiv.org/pdf/2505.00212
Code:https://github.com/mingyin1/Agents_Failure_Attribution
Dataset:https://huggingface.co/datasets/Kevin355/Who_and_When
Research Background and Challenges
LLM-driven Multi-Agent systems have demonstrated immense potential across many domains. However, these systems are fragile; errors by a single agent, misunderstandings between agents, or mistakes in information transmission can lead to the failure of the entire task.
Currently, when a system fails, developers are often left with manual and inefficient methods for debugging:
Manual Log Archaeology : Developers must manually review lengthy interaction logs to find the source of the problem.
Reliance on Expertise : The debugging process is highly dependent on the developer’s deep understanding of the system and the task at hand.
This “needle in a haystack” approach to debugging is not only inefficient but also severely hinders rapid system iteration and the improvement of system reliability. There is an urgent need for an automated, systematic method to pinpoint the cause of failures, effectively bridging the gap between “evaluation results” and “system improvement.”
Core Contributions
This paper makes several groundbreaking contributions to address the challenges above:
1. Defining a New Problem: The paper is the first to formalize “automated failure attribution” as a specific research task. This task is defined by identifying the failure-responsible agent and the decisive error step that led to the task’s failure.
2. Constructing the First Benchmark Dataset: Who&When : This dataset includes a wide range of failure logs collected from 127 LLM Multi-Agent systems, which were either algorithmically generated or hand-crafted by experts to ensure realism and diversity. Each failure log is accompanied by fine-grained human annotations for:
Who: The agent responsible for the failure.
When: The specific interaction step where the decisive error occurred.
Why: A natural language explanation of the cause of the failure.
3. Exploring Initial “Automated Attribution” Methods : Using the Who&When dataset, the paper designs and assesses three distinct methods for automated failure attribution:
– All-at-Once: This method provides the LLM with the user query and the complete failure log, asking it to identify the responsible agent and the decisive error step in a single pass. While cost-effective, it may struggle to pinpoint precise errors in long contexts.
– Step-by-Step: This approach mimics manual debugging by having the LLM review the interaction log sequentially, making a judgment at each step until the error is found. It is more precise at locating the error step but incurs higher costs and risks accumulating errors.
– Binary Search: A compromise between the first two methods, this strategy repeatedly divides the log in half, using the LLM to determine which segment contains the error. It then recursively searches the identified segment, offering a balance of cost and performance.
Experimental Results and Key Findings
Experiments were conducted in two settings: one where the LLM knows the ground truth answer to the problem the Multi-Agent system is trying to solve (With Ground Truth) and one where it does not (Without Ground Truth). The primary model used was GPT-4o, though other models were also tested. The systematic evaluation of these methods on the Who&When dataset yielded several important insights:
– A Long Way to Go: Current methods are far from perfect. Even the best-performing single method achieved an accuracy of only about 53.5% in identifying the responsible agent and a mere 14.2% in pinpointing the exact error step. Some methods performed even worse than random guessing, underscoring the difficulty of the task.
– No “All-in-One” Solution: Different methods excel at different aspects of the problem. The All-at-Once method is better at identifying “Who,” while the Step-by-Step method is more effective at determining “When.” The Binary Search method provides a middle-ground performance.
– Hybrid Approaches Show Promise but at a High Cost: The researchers found that combining different methods, such as using the All-at-Once approach to identify a potential agent and then applying the Step-by-Step method to find the error, can improve overall performance. However, this comes with a significant increase in computational cost.
– State-of-the-Art Models Struggle: Surprisingly, even the most advanced reasoning models, like OpenAI o1 and DeepSeek R1, find this task challenging.- This h…
Konten dipersingkat otomatis.
🔗 Sumber: syncedreview.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!