📌 TOPINDIATOURS Update ai: Adobe Research Unlocking Long-Term Memory in Video Worl
Video world models, which predict future frames conditioned on actions, hold immense promise for artificial intelligence, enabling agents to plan and reason in dynamic environments. Recent advancements, particularly with video diffusion models, have shown impressive capabilities in generating realistic future sequences. However, a significant bottleneck remains: maintaining long-term memory. Current models struggle to remember events and states from far in the past due to the high computational cost associated with processing extended sequences using traditional attention layers. This limits their ability to perform complex tasks requiring sustained understanding of a scene.
A new paper, “Long-Context State-Space Video World Models” by researchers from Stanford University, Princeton University, and Adobe Research, proposes an innovative solution to this challenge. They introduce a novel architecture that leverages State-Space Models (SSMs) to extend temporal memory without sacrificing computational efficiency.
The core problem lies in the quadratic computational complexity of attention mechanisms with respect to sequence length. As the video context grows, the resources required for attention layers explode, making long-term memory impractical for real-world applications. This means that after a certain number of frames, the model effectively “forgets” earlier events, hindering its performance on tasks that demand long-range coherence or reasoning over extended periods.
The authors’ key insight is to leverage the inherent strengths of State-Space Models (SSMs) for causal sequence modeling. Unlike previous attempts that retrofitted SSMs for non-causal vision tasks, this work fully exploits their advantages in processing sequences efficiently.
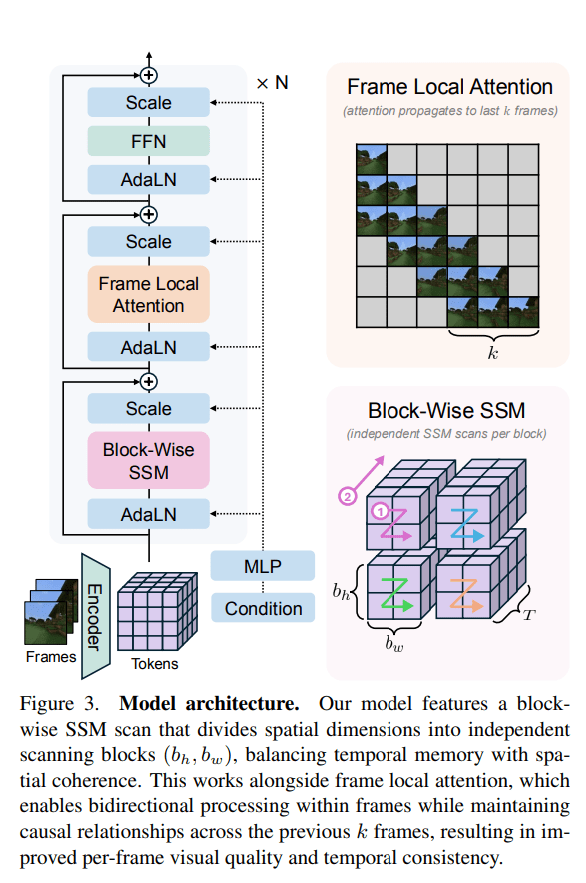
The proposed Long-Context State-Space Video World Model (LSSVWM) incorporates several crucial design choices:
- Block-wise SSM Scanning Scheme: This is central to their design. Instead of processing the entire video sequence with a single SSM scan, they employ a block-wise scheme. This strategically trades off some spatial consistency (within a block) for significantly extended temporal memory. By breaking down the long sequence into manageable blocks, they can maintain a compressed “state” that carries information across blocks, effectively extending the model’s memory horizon.
- Dense Local Attention: To compensate for the potential loss of spatial coherence introduced by the block-wise SSM scanning, the model incorporates dense local attention. This ensures that consecutive frames within and across blocks maintain strong relationships, preserving the fine-grained details and consistency necessary for realistic video generation. This dual approach of global (SSM) and local (attention) processing allows them to achieve both long-term memory and local fidelity.
The paper also introduces two key training strategies to further improve long-context performance:
- Diffusion Forcing: This technique encourages the model to generate frames conditioned on a prefix of the input, effectively forcing it to learn to maintain consistency over longer durations. By sometimes not sampling a prefix and keeping all tokens noised, the training becomes equivalent to diffusion forcing, which is highlighted as a special case of long-context training where the prefix length is zero. This pushes the model to generate coherent sequences even from minimal initial context.
- Frame Local Attention: For faster training and sampling, the authors implemented a “frame local attention” mechanism. This utilizes FlexAttention to achieve significant speedups compared to a fully causal mask. By grouping frames into chunks (e.g., chunks of 5 with a frame window size of 10), frames within a chunk maintain bidirectionality while also attending to frames in the previous chunk. This allows for an effective receptive field while optimizing computational load.
The researchers evaluated their LSSVWM on challenging datasets, including Memory Maze and Minecraft, which are specifically designed to test long-term memory capabilities through spatial retrieval and reasoning tasks.
The experiments demonstrate that their approach substantially surpasses baselines in preserving long-range memory. Qualitative results, as shown in supplementary figures (e.g., S1, S2, S3), illustrate that LSSVWM can generate more coherent and accurate sequences over extended periods compared to models relying solely on causal attention or even Mamba2 without frame local attention. For instance, on reasoning tasks for the maze dataset, their model maintains better consistency and accuracy over long horizons. Similarly, for retrieval tasks, LSSVWM shows improved ability to recall and utilize information from distant past frames. Crucially, these improvements are achieved while maintaining practical inference speeds, making the models suitable for interactive applications.
The Paper Long-Context State-Space Video World Models is on arXiv
The post Adobe Research Unlocking Long-Term Memory in Video World Models with State-Space Models first appeared on Synced.
🔗 Sumber: syncedreview.com
📌 TOPINDIATOURS Eksklusif ai: It’s Starting to Feel a Lot Like Tesla’s Robotaxi Pr
Elon Musk once promised that pivoting Tesla into the self-driving taxi business would generate the automaker trillions of dollars in revenue. Certainly the enthusiasm these kinds of grand proclamations have inspired in investors has kept the company’s stock buoyant, with an astonishing market cap nearing $1.5 trillion. But does the reality on the ground back it up? Not really, suggests new reporting from The New York Times.
For one, Tesla faces steep competition from companies like Waymo that have already been in business for over a decade, and have thousands of robotaxis giving rides across major US cities. It was recently revealed, meanwhile, that Musk’s company only has about 30 capital-R Robotaxis roaming Austin, Texas — the only city where it’s currently offering rides to the public.
Worse yet, the cabs’ presence is barely felt by locals.
“I’ve never seen a Robotaxi in Austin,” Kara Kockelman, a professor of engineering at the University of Texas at Austin who studies transportation, told the NYT. “Waymos are around all the time.”
Perhaps that puny market penetration would be less alarming if Tesla offered advanced tech and a passenger experience that Waymo doesn’t, but its self-driving cabs aren’t even fully driverless, requiring the supervision of a human “safety monitor” who must be present in the vehicle at all times. Numerous instances of the cabs violating traffic laws and an alarming crash rate demonstrate why that policy is still necessary.
It’s reasonable that a newcomer to the field would take time to find its feet, but Musk has promised monumental progress at a whirlwind pace. He said that over a thousand Robotaxis would be operating in Austin “within a few months” of launching, that over a million fully autonomous Teslas would be on the road by 2026, and that the automaker’s Robotaxi operations would cover “half the population of the US” by the end of next year.
Investors take these promises seriously. Musk’s eye-watering trillion-dollar pay package, which they recently approved, requires Musk to oversee the commercial deployment of one million Robotaxis, the NYT noted.
Experts, to say the least, aren’t convinced. One criticism is Musk’s refusal to use radar and lidar sensors to help the cars understand their surroundings. After experimenting with the sensors, Musk swore them off as an expensive “crutch,” and doubled-down on only using cameras to see. Numerous accidents, including one in which a Tesla running the company’s Full Self-Driving ran over and killed an elderly pedestrian while its front camera was blinded by sunlight, have underscored the risks of Musk’s approach.
“I’m still deeply skeptical that Tesla is all that close in terms of building a real automated driving system,” Matthew Wansley, a professor at Cardozo School of Law in New York who has worked for an autonomous driving start-up, told the NYT.
Technology can sometimes advance at a rapid pace, and fortunes can quickly shift in a nascent industry. But right now, Tesla is “way behind Waymo,” Raj Rajkumar, a Carnegie Mellon University professor and pioneer of autonomous technology, told the newspaper.
More on robotaxis: Waymos Cause Traffic Jams Across City During Power Outage
The post It’s Starting to Feel a Lot Like Tesla’s Robotaxi Program Is Mostly Smoke and Mirrors appeared first on Futurism.
🔗 Sumber: futurism.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!