📌 TOPINDIATOURS Breaking ai: Adobe Research Unlocking Long-Term Memory in Video Wo
Video world models, which predict future frames conditioned on actions, hold immense promise for artificial intelligence, enabling agents to plan and reason in dynamic environments. Recent advancements, particularly with video diffusion models, have shown impressive capabilities in generating realistic future sequences. However, a significant bottleneck remains: maintaining long-term memory. Current models struggle to remember events and states from far in the past due to the high computational cost associated with processing extended sequences using traditional attention layers. This limits their ability to perform complex tasks requiring sustained understanding of a scene.
A new paper, “Long-Context State-Space Video World Models” by researchers from Stanford University, Princeton University, and Adobe Research, proposes an innovative solution to this challenge. They introduce a novel architecture that leverages State-Space Models (SSMs) to extend temporal memory without sacrificing computational efficiency.
The core problem lies in the quadratic computational complexity of attention mechanisms with respect to sequence length. As the video context grows, the resources required for attention layers explode, making long-term memory impractical for real-world applications. This means that after a certain number of frames, the model effectively “forgets” earlier events, hindering its performance on tasks that demand long-range coherence or reasoning over extended periods.
The authors’ key insight is to leverage the inherent strengths of State-Space Models (SSMs) for causal sequence modeling. Unlike previous attempts that retrofitted SSMs for non-causal vision tasks, this work fully exploits their advantages in processing sequences efficiently.
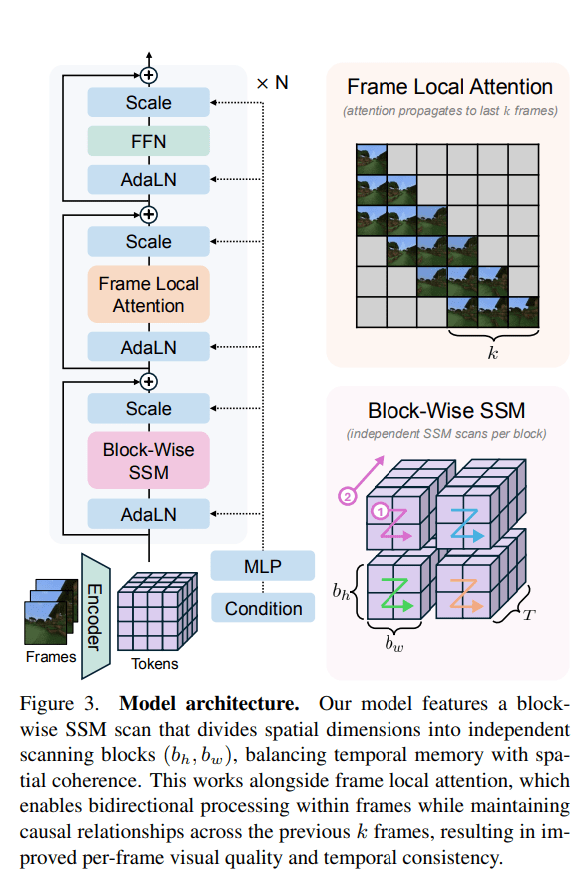
The proposed Long-Context State-Space Video World Model (LSSVWM) incorporates several crucial design choices:
- Block-wise SSM Scanning Scheme: This is central to their design. Instead of processing the entire video sequence with a single SSM scan, they employ a block-wise scheme. This strategically trades off some spatial consistency (within a block) for significantly extended temporal memory. By breaking down the long sequence into manageable blocks, they can maintain a compressed “state” that carries information across blocks, effectively extending the model’s memory horizon.
- Dense Local Attention: To compensate for the potential loss of spatial coherence introduced by the block-wise SSM scanning, the model incorporates dense local attention. This ensures that consecutive frames within and across blocks maintain strong relationships, preserving the fine-grained details and consistency necessary for realistic video generation. This dual approach of global (SSM) and local (attention) processing allows them to achieve both long-term memory and local fidelity.
The paper also introduces two key training strategies to further improve long-context performance:
- Diffusion Forcing: This technique encourages the model to generate frames conditioned on a prefix of the input, effectively forcing it to learn to maintain consistency over longer durations. By sometimes not sampling a prefix and keeping all tokens noised, the training becomes equivalent to diffusion forcing, which is highlighted as a special case of long-context training where the prefix length is zero. This pushes the model to generate coherent sequences even from minimal initial context.
- Frame Local Attention: For faster training and sampling, the authors implemented a “frame local attention” mechanism. This utilizes FlexAttention to achieve significant speedups compared to a fully causal mask. By grouping frames into chunks (e.g., chunks of 5 with a frame window size of 10), frames within a chunk maintain bidirectionality while also attending to frames in the previous chunk. This allows for an effective receptive field while optimizing computational load.
The researchers evaluated their LSSVWM on challenging datasets, including Memory Maze and Minecraft, which are specifically designed to test long-term memory capabilities through spatial retrieval and reasoning tasks.
The experiments demonstrate that their approach substantially surpasses baselines in preserving long-range memory. Qualitative results, as shown in supplementary figures (e.g., S1, S2, S3), illustrate that LSSVWM can generate more coherent and accurate sequences over extended periods compared to models relying solely on causal attention or even Mamba2 without frame local attention. For instance, on reasoning tasks for the maze dataset, their model maintains better consistency and accuracy over long horizons. Similarly, for retrieval tasks, LSSVWM shows improved ability to recall and utilize information from distant past frames. Crucially, these improvements are achieved while maintaining practical inference speeds, making the models suitable for interactive applications.
The Paper Long-Context State-Space Video World Models is on arXiv
The post Adobe Research Unlocking Long-Term Memory in Video World Models with State-Space Models first appeared on Synced.
🔗 Sumber: syncedreview.com
📌 TOPINDIATOURS Update ai: Digital resurrection: 6,000-year-old Japanese fishing n
For the first time ever, 6,000-year-old Japanese fishing nets have been digitally resurrected, revealing a lost era of prehistoric mastery.
In a groundbreaking archaeological study, researchers have digitally and physically reconstructed prehistoric fishing nets from Japan’s Jomon period, some of which are over 6,000 years old. This research, published in the Journal of Archaeological Science, is believed to be the first of its kind to reconstruct these nets in such detail, shedding light on ancient technology.
Using cutting-edge technology, a team from Kumamoto University analyzed impressions of nets preserved in pottery fragments from two different Japanese locations. They were able to restore the shape, thread twist, knot types, and mesh size of the nets that had decayed thousands of years ago.
This research not only reconstructs these lost craft techniques but also shows that nets were often repurposed for pottery making, which highlights the ingenuity and resourcefulness of the Jomon communities.
Regional differences in net-making
The team, led by Professor Emeritus Hiroki Obata, examined pottery fragments from two distinct regions: Hokkaido in the north and Kyushu in the south. Using high-resolution X-ray computed tomography (CT) scans and silicone cast replication, researchers were able to visualize the intricate net structures in exquisite detail.
Pottery from Hokkaido’s Early Jomon period, known as the Shizunai-Nakano style, contained large-mesh nets with tightly tied reef knots embedded in the clay coils. “Nets, not only utilized for ocean fishing, were also being reused as reinforcement when constructing pottery,” reports Archaeology Magazine.
However, the Final Jomon and early Yayoi period pottery from Kyushu preserved fine-mesh nets tied with simpler overhand knots or “knotted wrapping” techniques. According to the study, these smaller nets were likely used as bags, molds, or release agents during pottery production.
The research also revealed subtle regional differences in thread twist direction and knotting methods, reflecting cultural practices and practical considerations. The Hokkaido nets used an S2z twist, while the Kyushu nets displayed a Z2s twist, the study reports. Phys notes that “the small-mesh nets of less than 6.5 millimeters found in Kyushu pottery were probably not fishing nets at all but instead were used for other purposes, perhaps as containers.”
85 hours of work
Remarkably, the study estimated that crafting a single net could have taken more than 85 hours of labor. “This reuse of materials reflects an early form of sustainability, akin to today’s SDGs,” said Prof. Hiroki Obata of Kumamoto University, according to Phys. The findings challenge the long-held assumption that all fiber impressions on pottery were fishing gear, instead showing that nets were versatile tools with multiple uses in both daily life and craft production.
By combining CT scanning, silicone casting, and detailed 3D analysis, the study has resurrected the form and function of nets that have been lost for millennia. The researchers argue that understanding these net structures sheds light not only on fishing practices but also on pottery production, resource reuse, and cultural norms during the Jomon period. As Archaeology Magazine notes, this methodological breakthrough opens new doors for rediscovering vanished organic materials worldwide—from textiles to baskets—transforming how archaeologists can reconstruct prehistoric life.
The study has been published in the Journal of Archaeological Science.
🔗 Sumber: interestingengineering.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!