📌 TOPINDIATOURS Update ai: World-first 3D placentas print early tissue, test drugs
Scientists have 3D bioprinted miniature placentas, opening new ways to study pregnancy complications. The breakthrough comes from the University of Technology Sydney (UTS).
Pregnancy complications cause over 260,000 maternal deaths and millions of infant deaths every year. One serious condition linked to placental dysfunction is preeclampsia, affecting 5–8% of pregnancies.
Printing new pregnancy models
“Obtaining first-trimester placental tissue is not practical or safe, making early pregnancy challenging to study. By the time a baby is born, the placenta has changed so much that it no longer reflects what it was like in early pregnancy,” said Dr Lana McClements, the lead author of the study.
“Serious pregnancy complications like preeclampsia remain one of medicine’s great mysteries, largely because current animal and cell models cannot accurately replicate the human placenta,” she said.
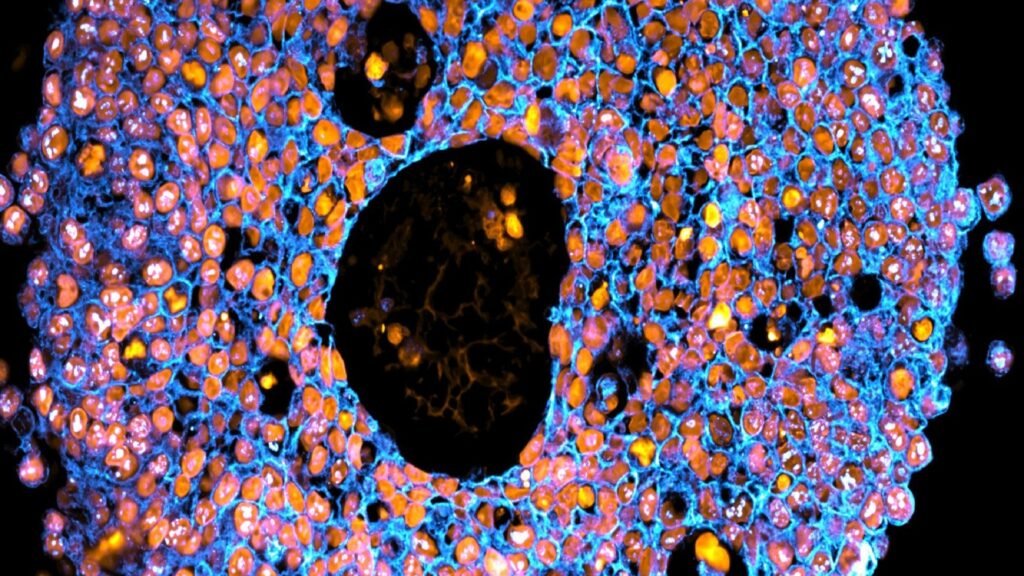
Miniature organs, called ‘organoids’, were first developed in 2009. They provide accurate models of human organs. Scientists grow them by taking stem cells and placing them in a gel that mimics tissue. The cells form clusters as they grow and divide.
In 2018, the first placental organoids were grown from trophoblasts – cells found only in the placenta. This marked a step forward in pregnancy research.
Bioprinting takes this further. It is a type of 3D printing that uses living cells and cell-friendly materials to create 3D structures. The UTS team mixed trophoblast cells with a synthetic gel. They printed them in precise droplets, much like an ink-jet office printer.
“Our printed cells grew into placental organoids and we compared them to organoids made via traditional manual methods,” said Dr Claire Richards from the UTS School of Life Sciences, who is also the first author the study.
“The organoids we grew in the bioprinted gel developed differently to those grown in an animal-derived gel, and formed different numbers of trophoblast sub-types. This highlighted that the environment organoids are grown in can control how they mature.”
Safer drug testing models
The bioprinted organoids closely resembled human placental tissue. This allows scientists to study the early placenta safely. It could help understand why some pregnancies go wrong.
“We showed these organoids were very similar to human placental tissue, providing an accurate model of the early placenta. This means we can start piecing together the puzzle of pregnancy complications and test new drugs safely,” Dr Richards said.
“For example, we exposed our bioprinted organoids to an inflammatory molecule found at high levels in women with preeclampsia, then tested potential treatments to see how the organoids grew and responded.”
The team hopes to refine these models further. The goal is a future where pregnancy complications can be predicted, prevented, and treated before they put lives at risk.
“As we refine these models, we move closer to a future where pregnancy complications can be predicted, prevented and treated before they put lives at risk,” said Dr Richards.
This breakthrough combines 3D bioprinting, organoid technology, and placental research. It may pave the way for safer drugs, a better understanding of preeclampsia, and lower risks for mothers and babies worldwide.
The findings have been published in the journal Nature Communications.
🔗 Sumber: interestingengineering.com
📌 TOPINDIATOURS Breaking ai: Which Agent Causes Task Failures and When?Researchers
Share My Research is Synced’s column that welcomes scholars to share their own research breakthroughs with over 1.5M global AI enthusiasts. Beyond technological advances, Share My Research also calls for interesting stories behind the research and exciting research ideas. Contact us: chain.zhang@jiqizhixin.com
Meet the authors
Institutions: Penn State University, Duke University, Google DeepMind, University of Washington, Meta, Nanyang Technological University, and Oregon State University. The co-first authors are Shaokun Zhang of Penn State University and Ming Yin of Duke University.
In recent years, LLM Multi-Agent systems have garnered widespread attention for their collaborative approach to solving complex problems. However, it’s a common scenario for these systems to fail at a task despite a flurry of activity. This leaves developers with a critical question: which agent, at what point, was responsible for the failure? Sifting through vast interaction logs to pinpoint the root cause feels like finding a needle in a haystack—a time-consuming and labor-intensive effort.
This is a familiar frustration for developers. In increasingly complex Multi-Agent systems, failures are not only common but also incredibly difficult to diagnose due to the autonomous nature of agent collaboration and long information chains. Without a way to quickly identify the source of a failure, system iteration and optimization grind to a halt.
To address this challenge, researchers from Penn State University and Duke University, in collaboration with institutions including Google DeepMind, have introduced the novel research problem of “Automated Failure Attribution.” They have constructed the first benchmark dataset for this task, Who&When, and have developed and evaluated several automated attribution methods. This work not only highlights the complexity of the task but also paves a new path toward enhancing the reliability of LLM Multi-Agent systems.
The paper has been accepted as a Spotlight presentation at the top-tier machine learning conference, ICML 2025, and the code and dataset are now fully open-source.
Paper:https://arxiv.org/pdf/2505.00212
Code:https://github.com/mingyin1/Agents_Failure_Attribution
Dataset:https://huggingface.co/datasets/Kevin355/Who_and_When
Research Background and Challenges
LLM-driven Multi-Agent systems have demonstrated immense potential across many domains. However, these systems are fragile; errors by a single agent, misunderstandings between agents, or mistakes in information transmission can lead to the failure of the entire task.
Currently, when a system fails, developers are often left with manual and inefficient methods for debugging:
Manual Log Archaeology : Developers must manually review lengthy interaction logs to find the source of the problem.
Reliance on Expertise : The debugging process is highly dependent on the developer’s deep understanding of the system and the task at hand.
This “needle in a haystack” approach to debugging is not only inefficient but also severely hinders rapid system iteration and the improvement of system reliability. There is an urgent need for an automated, systematic method to pinpoint the cause of failures, effectively bridging the gap between “evaluation results” and “system improvement.”
Core Contributions
This paper makes several groundbreaking contributions to address the challenges above:
1. Defining a New Problem: The paper is the first to formalize “automated failure attribution” as a specific research task. This task is defined by identifying the failure-responsible agent and the decisive error step that led to the task’s failure.
2. Constructing the First Benchmark Dataset: Who&When : This dataset includes a wide range of failure logs collected from 127 LLM Multi-Agent systems, which were either algorithmically generated or hand-crafted by experts to ensure realism and diversity. Each failure log is accompanied by fine-grained human annotations for:
Who: The agent responsible for the failure.
When: The specific interaction step where the decisive error occurred.
Why: A natural language explanation of the cause of the failure.
3. Exploring Initial “Automated Attribution” Methods : Using the Who&When dataset, the paper designs and assesses three distinct methods for automated failure attribution:
– All-at-Once: This method provides the LLM with the user query and the complete failure log, asking it to identify the responsible agent and the decisive error step in a single pass. While cost-effective, it may struggle to pinpoint precise errors in long contexts.
– Step-by-Step: This approach mimics manual debugging by having the LLM review the interaction log sequentially, making a judgment at each step until the error is found. It is more precise at locating the error step but incurs higher costs and risks accumulating errors.
– Binary Search: A compromise between the first two methods, this strategy repeatedly divides the log in half, using the LLM to determine which segment contains the error. It then recursively searches the identified segment, offering a balance of cost and performance.
Experimental Results and Key Findings
Experiments were conducted in two settings: one where the LLM knows the ground truth answer to the problem the Multi-Agent system is trying to solve (With Ground Truth) and one where it does not (Without Ground Truth). The primary model used was GPT-4o, though other models were also tested. The systematic evaluation of these methods on the Who&When dataset yielded several important insights:
– A Long Way to Go: Current methods are far from perfect. Even the best-performing single method achieved an accuracy of only about 53.5% in identifying the responsible agent and a mere 14.2% in pinpointing the exact error step. Some methods performed even worse than random guessing, underscoring the difficulty of the task.
– No “All-in-One” Solution: Different methods excel at different aspects of the problem. The All-at-Once method is better at identifying “Who,” while the Step-by-Step method is more effective at determining “When.” The Binary Search method provides a middle-ground performance.
– Hybrid Approaches Show Promise but at a High Cost: The researchers found that combining different methods, such as using the All-at-Once approach to identify a potential agent and then applying the Step-by-Step method to find the error, can improve overall performance. However, this comes with a significant increase in computational cost.
– State-of-the-Art Models Struggle: Surprisingly, even the most advanced reasoning models, like OpenAI o1 and DeepSeek R1, find this task challenging.- This h…
Konten dipersingkat otomatis.
🔗 Sumber: syncedreview.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!