📌 TOPINDIATOURS Hot ai: Adobe Research Unlocking Long-Term Memory in Video World M
Video world models, which predict future frames conditioned on actions, hold immense promise for artificial intelligence, enabling agents to plan and reason in dynamic environments. Recent advancements, particularly with video diffusion models, have shown impressive capabilities in generating realistic future sequences. However, a significant bottleneck remains: maintaining long-term memory. Current models struggle to remember events and states from far in the past due to the high computational cost associated with processing extended sequences using traditional attention layers. This limits their ability to perform complex tasks requiring sustained understanding of a scene.
A new paper, “Long-Context State-Space Video World Models” by researchers from Stanford University, Princeton University, and Adobe Research, proposes an innovative solution to this challenge. They introduce a novel architecture that leverages State-Space Models (SSMs) to extend temporal memory without sacrificing computational efficiency.
The core problem lies in the quadratic computational complexity of attention mechanisms with respect to sequence length. As the video context grows, the resources required for attention layers explode, making long-term memory impractical for real-world applications. This means that after a certain number of frames, the model effectively “forgets” earlier events, hindering its performance on tasks that demand long-range coherence or reasoning over extended periods.
The authors’ key insight is to leverage the inherent strengths of State-Space Models (SSMs) for causal sequence modeling. Unlike previous attempts that retrofitted SSMs for non-causal vision tasks, this work fully exploits their advantages in processing sequences efficiently.
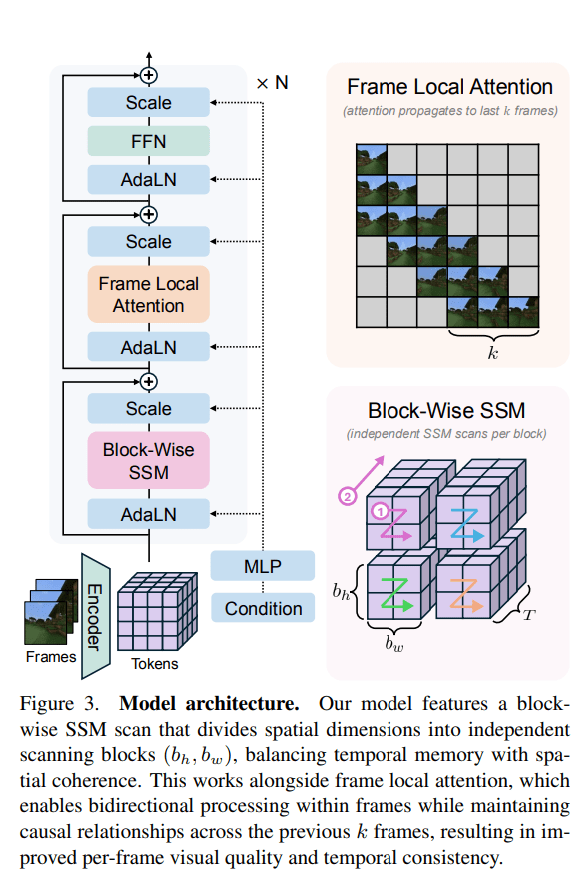
The proposed Long-Context State-Space Video World Model (LSSVWM) incorporates several crucial design choices:
- Block-wise SSM Scanning Scheme: This is central to their design. Instead of processing the entire video sequence with a single SSM scan, they employ a block-wise scheme. This strategically trades off some spatial consistency (within a block) for significantly extended temporal memory. By breaking down the long sequence into manageable blocks, they can maintain a compressed “state” that carries information across blocks, effectively extending the model’s memory horizon.
- Dense Local Attention: To compensate for the potential loss of spatial coherence introduced by the block-wise SSM scanning, the model incorporates dense local attention. This ensures that consecutive frames within and across blocks maintain strong relationships, preserving the fine-grained details and consistency necessary for realistic video generation. This dual approach of global (SSM) and local (attention) processing allows them to achieve both long-term memory and local fidelity.
The paper also introduces two key training strategies to further improve long-context performance:
- Diffusion Forcing: This technique encourages the model to generate frames conditioned on a prefix of the input, effectively forcing it to learn to maintain consistency over longer durations. By sometimes not sampling a prefix and keeping all tokens noised, the training becomes equivalent to diffusion forcing, which is highlighted as a special case of long-context training where the prefix length is zero. This pushes the model to generate coherent sequences even from minimal initial context.
- Frame Local Attention: For faster training and sampling, the authors implemented a “frame local attention” mechanism. This utilizes FlexAttention to achieve significant speedups compared to a fully causal mask. By grouping frames into chunks (e.g., chunks of 5 with a frame window size of 10), frames within a chunk maintain bidirectionality while also attending to frames in the previous chunk. This allows for an effective receptive field while optimizing computational load.
The researchers evaluated their LSSVWM on challenging datasets, including Memory Maze and Minecraft, which are specifically designed to test long-term memory capabilities through spatial retrieval and reasoning tasks.
The experiments demonstrate that their approach substantially surpasses baselines in preserving long-range memory. Qualitative results, as shown in supplementary figures (e.g., S1, S2, S3), illustrate that LSSVWM can generate more coherent and accurate sequences over extended periods compared to models relying solely on causal attention or even Mamba2 without frame local attention. For instance, on reasoning tasks for the maze dataset, their model maintains better consistency and accuracy over long horizons. Similarly, for retrieval tasks, LSSVWM shows improved ability to recall and utilize information from distant past frames. Crucially, these improvements are achieved while maintaining practical inference speeds, making the models suitable for interactive applications.
The Paper Long-Context State-Space Video World Models is on arXiv
The post Adobe Research Unlocking Long-Term Memory in Video World Models with State-Space Models first appeared on Synced.
🔗 Sumber: syncedreview.com
📌 TOPINDIATOURS Hot ai: Murder of MIT Fusion Scientist Getting More and More Bizar
Last week, lauded theoretical physicist and director of the MIT Plasma Science and Fusion Center Nuno Loureiro was murdered in his home in Brookline, Massachusetts.
Since then, investigators have made several breakthroughs in the unusual case, linking the prime suspect to a separate deadly mass shooting at Brown University earlier in December.
The suspected shooter, Claudio Neves Valente, was found dead in a storage unit in New Hampshire on Thursday following a six-day manhunt. But as bizarre twists add up in the case, investigatorsand the surviving loved ones of his victims are left with more questions than answers.
As the Wall Street Journal reported over the weekend, Neves Valente, a physics graduate from Portugal, had a reputation for being difficult in class, despite being remembered fondly by others.
Perhaps most bafflingly, Neves Valente attended the same school — Lisbon’s Instituto Superior Técnico — as his future victim, Loureiro, where they were both students between 1995 and 2000, CNN confirmed. Neves Valente eventually pursued his graduate studies at Brown, linking him to the second institution where he’s suspected of committing a deadly shooting.
Former Brown physics professor Scott Watson, who spent a lot of time with Neves Valente at Brown, said he became “sometimes angry” about life at Brown in esoteric ways — complaining about the quality of the fish he was served, for instance.
“He would say the classes were too easy — honestly, for him they were. He already knew most of the material and was genuinely impressive,” Watson told the Associated Press.
Neves Valente left Brown in early 2001 and returned to Portugal to work for a telecom.
Classmates have suggested he may have become jealous of Loureiro’s illustrious career.
Roughly an hour before Neves Valente opened fire on students in a Brown lecture hall, a witness noticed he was wearing a mask and flimsy clothing, leading to an altercation, per the WSJ.
“Why are you harassing me?” he told the witness angrily after being followed and confronted.
All told, Neves Valenete killed three individuals and injured nine.
It’s a tragic story that still leaves plenty of questions unanswered. Why did Neves Valente single out his former classmate? Was there more to his desire to inflict harm on others?
“Claudio was obviously one of the best, but in class he had a great need to stand out and show that he was better than the rest,” former classmate Felipe Moura wrote in a Facebook post, as quoted by CNN.
“I never expected he would be capable of such a thing,” he added.
More on the murder: MIT Fusion Physicist Murdered in His Home
The post Murder of MIT Fusion Scientist Getting More and More Bizarre appeared first on Futurism.
🔗 Sumber: futurism.com
🤖 Catatan TOPINDIATOURS
Artikel ini adalah rangkuman otomatis dari beberapa sumber terpercaya. Kami pilih topik yang sedang tren agar kamu selalu update tanpa ketinggalan.
✅ Update berikutnya dalam 30 menit — tema random menanti!